主页 > imtoken被检测为风险软件 > 如何将比特币区块链数据导入关系数据库
如何将比特币区块链数据导入关系数据库
接触比特币和区块链之后,我一直有个想法,就是把比特币的区块链数据全部放到一个关系型数据库(比如SQL Server)中,然后作为数据仓库来使用对比特币交易数据进行各种分析。这个想法由来已久,但一直没有付诸实施。最近有一段时间,所以我为比特币区块链编写了一个导出和导入程序。
我之前的一篇博客:区块链上的告白——用C#在比特币区块链里放一句话描述了如何发起比特币交易,今天我们还是用C#+NBitcoin来读取全量区块链数据从比特币钱包Bitcoin Core下载到本地,并将数据写入数据库。如果有和我有相同想法的朋友可以参考以下是我的操作流程:
一、准备工作
我们要解析的是存储在本地硬盘上的比特币Core钱包中的全部比特币数据,那么首先要做的就是下载安装Bitcoin Core,下载地址:然后等待这个软件同步区块链数据。目前比特币的区块链数据在130G左右,因此可能需要几天甚至一周的时间才能将所有区块链数据同步到本地。当然,如果您尽早安装该软件,那就太好了,毕竟等待几天甚至一周真的很痛苦。
二、构建比特币区块链数据模型
要分析区块链数据,你必须了解区块链的数据模型。我研究了一下,可以总结出4个实体:块、交易、输入、输出。关系是一个区块对应多个交易,一个交易对应多个输入和多个输出。除了 Coinbase 的输入之外,一个输入对应于另一个交易中的一个输出。所以我们可以画出这样的数据模型:
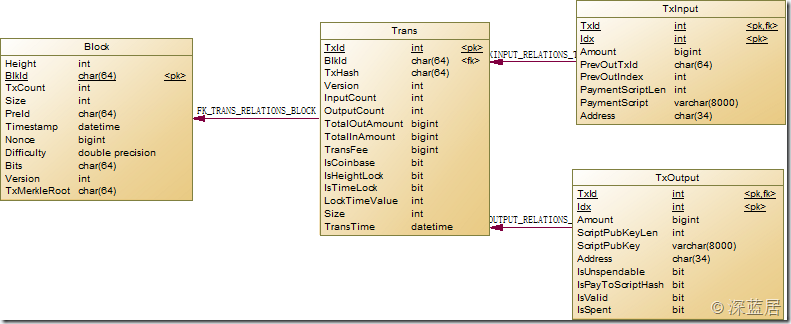
需要指定一些点:
1.TxId 它是一个自增的int。我没有使用 TxHash 作为 Transaction 的 PK,因为 TxHash 根本不是唯一的!有几个不同的区块,其中第一个交易,即 Coinbase 交易,是相同的。这其实应该是异常数据,因为同一个TxHash只会用一次,所以这个矿工有杯。
2.对于coinbase事务,输入preouttxid是0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000,及其preOutIndex is of -efteriits is non -efteriits innon -extelption toput。
3. For blocks, preid is the ID of the previous Block, and the preid of the creation block is 0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000, .
4.有很多字段实际上并不在区块链数据结构中。这些字段都是我添加的,方便后续分析。导入的时候是没有值的,需要经过一定的SQL操作后获取。比如Trans中的TotalInAmount、TransFee等。
我使用 PowerDesigner。建模完成后,即可生成SQL语句。这是我创建表的 SQL:

查看代码
三、将区块链数据导出为 CSV
p>
有了数据模型,接下来就是创建对应的表比特币钱包数据文件,然后编写程序将Bitcoin Block写入数据库。我最初使用EntityFramework来实现插入数据库的操作。但后来我发现它太慢了。插入一个块甚至需要超过 10 秒和 20 秒。我花了什么年份和月份插入它!尝试过各种方案,比如写原生SQL、使用事务、使用LINQToSQL等,但性能并不理想。最后找到了一个好办法,就是直接导出成文本文件(比如CSV格式),然后用SQL Server的Bulk Insert命令实现批量导入,这是我所知道的最快的写入数据库的方法.
开源库NBitcoin用于解析Bitcoin Core下载的所有比特币区块链数据。只需使用其中的 BlockStore 类即可轻松解析区块链数据。
这是我将区块链数据解析为我们的 Block 对象的代码:
查看代码
WriteBitcoin2Csv方法就是将Block、Trans、TxInput、TxOutput这四个对象以一定的格式写入四个文本文件中。
四、将 CSV 导入 SQL Server
导出 CSV 文件后,下一步是如何将 CSV 文件导入 SQL Server。这很简单,只需执行 BULK INSERT 命令即可。例如,这是我在测试时使用的 SQL 语句:
bulk insert [Block] from 'F:\temp\blk205867.csv'; bulk insert Trans from 'F:\temp\trans205867.csv'; bulk insert TxInput from 'F:\temp\input205867.csv'; bulk insert TxOutput from 'F:\temp\output205867.csv';
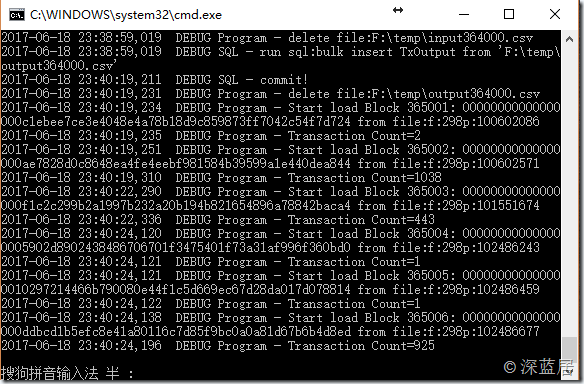
当然,在实践中比特币钱包数据文件,我不会这样做。我每1000个块生成4个csv文件,然后用C#连接数据库,执行批量插入命令。执行完成后,删除生成的4个csv文件,然后循环继续导出下一批1000个block。因为比特币区块链数据太大了,不批量的话,我的PC硬盘就不够用了,导入SQL Server的时候,我怀疑能不能导入这么大批量的数据。
最后,我附上我正在导入的流程图。导入一天了,还没完成。估计还要一、两天。
区块链数据全部入库后,我得发挥想象力,看看能分析出什么有趣的结果。